I held a presentation on this project on Elixir MeetUp Berlin on Feb 8th, 2024. The slides can be found here.
The Livebook code can be found here. The code for data collection can be found here.
Abstract
We try to predict voting result in the 2023 Bavarian state election in Germany by Mastodon posts.
The last polls before the election show an average error of about 0.7 to 0.9 percent per major party. A time weighted average of the polls of the last six weeks before the election reduced the error to 0.39 percentage points per party.
We apply frequency based and sentiment based methods on the posts:
- frequency based
- Bavarian or other German posts: between Aug. 29th and Oct. 7th.
- Bavarian or other German posts: between Sep. 17th and Oct. 7th.
- Most positive post per Bavarian or other German author: between Sep. 17th and Oct. 7th.
- sentiment based
- weighted weekly sentiment.
- fit of weekly averaged polls versus weekly averaged sentiments.
We have a total of 160 Bavarian users with evaluable posts. The sample size is to low to ensure high significance to represent the population. Applying frequency based methods on the Mastodon posts shows a best error of 4.4 percentage points per party. If we fit the polls versus the sentiment, we get an error 0.40 percentage points per party compared to the election result. While the average of the polls in the last six weeks have an error 0.39. The dependency on the sentiment is only about 2.5 percentage points the rest can be attributed to the parties themselves.
Introduction
Mastodon1 is a micro blogging service that is federated by the ActivityPub protocol and part of the fediverse.2 Depending on the source Mastodon has about 8.4 million users world wide,3 or 14.4 M users both on Oct. 10th 2023.4
We started the monitoring on Aug. 29th 2023. The end date of data generation was Nov. 19th 2023. The Aiwanger affaire took place at the beginning of the period. The daily news paper the SZ published an article that states that the Bavarian vice minister president and candidate of the FW Hubert Aiwanger5 was carrying an anti-Semitic pamphlet in is satchel when he was 17 years old.6
A study by the public service broadcasting stations ARD and ZDF shows that about two percent of all Germans, of both women an man are weekly recurring Mastodon users. This means about 1.7 M weekly recurring users from Germany. Mastodon reaches up to three percent for those aged 14 to 49.7 Because many services (and their instances) are able to federate with each other, it is possible to read posts from other services like Misskey, Lemmy, Pixelfed, Wordpress-Blogs.
Mastodon instances are often centred around a topic or a region. There is a high number of regional instances.8 Many are German. Mastodon had a strong spike in usage in Nov. 2022 with 2.5 M monthly recurrent users. Currently the network has still 1.6 million monthly recurrent users.9 We analyse Mastodon toots with the topic Bavaria state election which took place on Oct. 8th 2023. We apply a sentiment analysis. Sentiment analysis is used in natural language processing. The aim is recognise positive, neutral, or negative attitude within the text.10 We attempt to differentiate into Bavaria and other German regions.
We use the sentiment and frequency of mentioned persons and parties (see tab. 1). We do not consider favourisation, reblogs or replies. In addition, we did not try to monitor voting intention.11 We will use the terms posts and toots interchangeably. We call a user that wrote a particular post an author. One limiting issue is the sample size of users that use the Mastodon and other federated services. The other is demographics.
Monitored Parties
The sentiment was monitored for the candidates and parties12 in tab. 1.13
| Party | Candidate(s) | Percentage 2018 | Percentage 2023 |
|---|---|---|---|
| AfD | Katrin Ebner-Steiner & Martin Böhm | 10.2 | 14.6 |
| CSU | Markus Söder | 37.2 | 37.0 |
| FDP | Martin Hagen | 5.1 | 3.0 |
| Freie Waehler | Hubert Aiwanger | 11.6 | 15.8 |
| Gruene | Ludwig Hartmann & Katharina Schulze | 17.6 | 14.4 |
| SPD | Florian von Brunn | 9.7 | 8.4 |
| Linke | Adelheid Rupp | 3.2 | 1.5 |
Methods
We have two phases in the project. The first phase is monitoring the data from Mastodon. In the second phase we try to use the posts from Mastodon to predict the voting outcome.
Monitoring
Following tags are monitored on the instance chaos.social. We group the tags by topics (see tab. 2).
| Category | Keywords |
|---|---|
| Bavaria | bayern, bayernwahl, bayernwahl2023 |
| Election | wahlen, wahlkampf, wahlumfrage, wahlen23, wahlen2023 |
| Partys | spd, csu, gruene, grune, gruenen, grunen, afd, freiewaehler, freiewahler, fw, fpd, linke |
| Candidates | markussoeder, markussoder, soeder, soder, hubertaiwanger, aiwanger, hartmann, martinhagen, ebnersteiner |
Some candidates were not included, because their names were not used as tags at the beginning of the study. We only used German words as tags.
A wide set of topics have been selected to retrieve a maximum of tagged posts. Due to the concept of federation of instances, it is possible that not all instances share posts, or not all posts. Still, only a single instance has been monitored to reduce the need of removing duplicates with different ids on each instance.
Search of posts without the need of tags has been released during the monitoring with Mastodon version 4.2 in the end of Sep. 2023. It was added on Oct. 3rd on chaos.social. Reindexing has been finished on Oct. 5th. We added search on Oct. 7th to the monitoring, the day before the election. The end date of data generation was Nov. 19th 2023.
We retrieve the tags via the public timeline of the instance and the search via the search api:
- {{instance_url}}/api/v1/timelines/tag/{{tag_name}}
- {{isntance_url}}/api/v2/search?q={{search_word}}
Search of tags in the public timeline is done without a login; therefore, only public posts are monitored. For the search a bearer token is needed. During the addition of the search the limit of requested post was increased from 20 (default) to 40 (maximum).
The posts are requested every full hour starting Aug. 29th 2023. The retrieval is done with a Elixir program that runs on Erlang’s BEAM runtime, to increase stability. Each post is written into four tables of a SQLite3 database. The toots table contains the post itself and some of its meta data. The users table contains some meta data of the posts about the users, who wrote the posts. The related table fields contains the fields a user can set using key value pairs, to add some information about him-/herself. The related tags table contains all tags of each post.
Depending on the search term and how often it is used in posts, the time range of a look back of 20/40 posts varies. For some search terms that are less frequently used, it lasts back several years. For other terms it ranges back several days only. This behaviour partially heals interruptions in the monitoring service.
Data Analysis
After retrieving the first batch of data, we start with a subsample, with the data of the first twelve days. While we still fetch new data. The subsample is used to create and test a work flow for the data analysis.
Data Preparation
The evaluation is done in an Elixir Livebook. First exploration was done on a sub-sample of the dataset, which was recorded until Sep. 10th 2023, about 12 days of full records. This dataset was used to fine tune the analysis. This notebook is than applied on the full-sample. The texts are cleaned to exclude:
- Html tags.
- Links.
- Characters: #, @, and _ .
- Removed double spaces.
The decision whether a post can be used for further analysis is done by filtering in three stages:
- Cleaned text contains more than 50 characters of cleaned text.
- Keep only posts specific to the region Bavaria.
- Keep only posts that is attributable to a single or dominant party.
Regional Filter
The regional filter accepts any post that abides to any of the the three rules:
- (Raw) post must name of any local entity.
- (Raw) post must name of any candidate.
- (Raw) post must name
CSU(single regional party).
We use 3890 local entities from the state name down to village names. We do not use the 7860 sub-district names as their number is much higher and includes some major common German words (e.g. Gern, Oder). This is also partially true for villages names (e.g. Wald). This filter method may also keep posts which mention similar names in other regions of the world.
Attribute Sentiment to Party
To select (raw) posts that’s sentiment can be attributed to a party, we test two methods:
- Keep posts that only name a single party or their candidate(s).
- Keep posts that contains a dominant party that is mentioned more often than all other party combined.
Spatial Differentiation
Based on OSM - Mastodon server, Mastodon instances are estimated to be used by Bavarian users (see List of Bavarian Instances in the Appendix).8 In addition, the fields and notes of each user are scanned for Bavarian location names by Bavarian State Office for Survey and Geoinformation from the state name down to village name (see fig. 1).14

that is used to differentiate between
Bavarian, German and Other.
Personal information can be stored in the use profile, e.g. in the user fields und the user text. The fields are key value stores which is a precise method to store the data. Location names that are common German words will not be misunderstood, whereas locations with same names, but in different regions are kept. If filtering by the user text, we can not filter by the keys above, but rely on the entity names alone. The full region selection algorithm is shown below.
Sentiment Analysis
The minimum of 50 characters was used to reduce the misclassification that may happen on shorter texts. The posts all contain a language label, but this is set by the user or his/her application and is therefore error prone. We detect the language by the roberta base language detection model with a limit 0f 100 tokens.15 The German sentiment analysis is done with the German sentiment bert model.16 We use the maximum limit of 512 possible tokens of the model. We only use the first 512 tokens and do not combine the analysis of multiple sections of the text. 512 tokens is far longer than the maximum post length of Mastodon of 500 characters as default. OPENAI estimates 4 characters per token, but this figure does vary per language and tokenizer.17 The German Sentiment Bert model is available as a python package. We applied the alternative to use the Elixir library Bumblebee. The English language posts are evaluated with the bertweet model with the limit of 130 tokens (see fig. 2).18
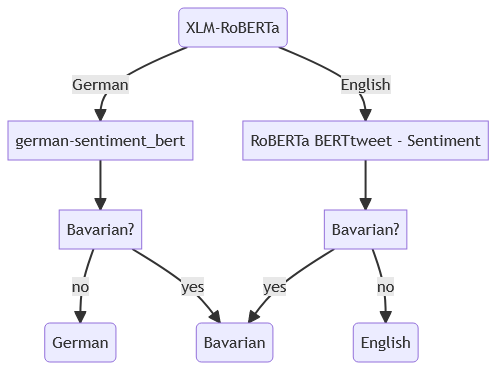
models used for sentiment analysis
for the regions Bavarian, (other) German,
and English.
The whole language classification process is shown below. The sentiment is mapped from the three classes (positive, negative, neutral) to a range -1 (negative) to 1 (positive).
Sentiment Graphs
The Sentiment is shown for the following regions:
- Bavaria.
- Other German.
For all parties most sentiments are neutral or negative. Irony detection is not included.19
Correlate Polls and Sentiments
The polls which have a start and end date are converted into a daily and weekly timeline for each party. For the daily poll timeline each day form start day to end day is unrolled and given the poll results for a certain party. If a day has a value estimated by different polling agencies, the poll results are averaged for each party. Missing daily values are filled with forward feed first and then with a backward feed. The days are encoded as day of the year. For the weekly timeline we take median day when each poll was executed. This median day was converted into a calendar week. If different polls were made, the results are averaged for each party. The daily and weekly sentiment data were converted and filled in a similar fashion. The timelines are aligned in time by latest start date and earliest end date. The alignments in values is done by converting the poll results into fractions and mapping the range of the sentiment values of -1 to 1 to a ratio of the sentiments of all parties from 0 to 1.
We want to estimate either the polling or sentiment time line delayed, and how long. Therefore we estimate the cross correlation between the timelines. We adjust the timelines further by the offset between them. For the adjusted timeline we estimate the linear regression between sentiment and polling.
Results
As a reference the sentiment analysis will be compared to polls.
Polls
Polls from different sources are listed at wahlrecht.de.20 With that we construct the timeline of a meta poll. The timeline for each party is shown below. The emphasis local changes in the fit, we apply the Locally estimated Scatterplot Smotting (Loess) fit with a bandwidth of 0.5 on the median datetime of each poll in dark red. The result of the election is shown as a blue line.
The strongest party CSU loses about three percent points since the start of the year 2023 with an result of 37 % at the election. In contrast, its coalition partner Freie Waehler (FW) increases by five percent points and wins 15.8 % of all votes.
Opposition parties show a trend of loosing on the left spectrum and gaining in the far right spectrum (AFD) (see fig. 3 and 4).12

Graphic showing the polls for the CSU
over the year 2023 until the election day.

Graphic showing the polls for the FW
over the year 2023 until the election day.

Graphic showing the polls for
Buendis 90 Gruene over the year 2023
until the election day.

Graphic showing the polls for the SPD
over the year 2023 until the election day.
Since the Linke only wins less then minimum 5 percent in every poll, it is only listed by some polling institute.

Graphic showing the polls for the AFD
over the year 2023 until the election day.
Both Linke and FDP did not meet the minimum of five percent. We therefore decided to omit the graphs.
Overall the fit of polls for each party is less than one percent of the election result.
The last polls before the election were conducted by Forschungsgruppe Wahlen and INSA.
Forschungsgruppe Wahlen shows an average error per party of 0.87 percent points and INSA 0.73 percentage points.
The larger error for Forschungsgruppe Wahlen is caused as they did not add an estimation for Die Linke.
Posts
In the sub-sample the cleaned posts with more than 50 characters in the evaluation data set contain 217 (median) and 248 ± 189 (average and standard deviation) characters. The maximum was above 5000 characters. While in the full-sample this changes to 281 ± 358 with a maximum of over 19000 characters and a median of 228 characters. Since only German words were selected as search terms, the amount of English posts is very limited.
We tried two different strategies for keeping posts that are attributable to single parties. In the first strategy we only keep posts that mention a single party, or their candidate(s). In the sub-sampled we thus keep 39 % of all posts.
The second strategy keeps all posts, that mention a party more often than, all other parties combined. In the sub-sample this kept 49 % of all posts. The connection between post and party is more clear with the first strategy, but we choose the second one, as more posts are preserved.
In addition, we changed the regional and party filter from the cleared posts to the raw posts. Cleaning removes, html-code. This includes also tags that are not mentioned in text. This way, we can still use the tags and keep 58 % percent of the posts of the sub-sample. The aggressive strategy, to keep as many posts as possible, was used, because the Linke, SPD, Gruene, and FDP had a very low count of left posts in the sub-sample, less than 10 posts per party. We do get the impression that this has also changed due to changes in the monitoring later on, which seams to have an retroactive effect for the smaller parties.
Of the sub-sample dataset we thus label 8.1 % of posts as Bavarian, 6.14 % due the uses instance, 0.4 % due to a Bavarian location name in the user field and 2.0 % due to a Bavarian location name in the user notes. After filtering the sub-samples contains 2647 toots of which we estimates 96 as Bavarian and 927 as other German.
In the full-sample 307 users (3.88 % percent) are from Bavaria: 2.68 % percent due to their Mastodon instance, 0.18 % due to their user fields and 1.18 % due to their user notes in total. In contrast, if we only consider posts that were kept after filtering, we keep 160 (8.9 %) Bavarian users and 1628 other German users. We thus kept 549 toots (10.0 %) as Bavarian and 4235 toots as other German, although more than 15 % of German inhabitants are Bavarian (see tab. 3 and 4).
| Posts | Sub-Sample | Full Sample |
|---|---|---|
| Total Count | 4563 | 33142 |
| Topic: Bavaria | 3363 | 10001 |
| With dominant Party | 2627 | 5763 |
| Bavarian Posts | 249 | 549 |
| Other German Posts | 2255 | 4921 |
| Users | Sub-Sample | Full Sample |
|---|---|---|
| Total Count | 1547 | 7918 |
| Thereof, Bavaria Users | 126 | 307 |
| German Users, After Filtering | 1023 | 1788 |
| Thereof, Bavaria Users | 96 | 160 |
| Thereof, Other German Users | 927 | 1628 |
Most posts (91.5 %) where self-labelled as German. Language classification increased this percentage to 97.7 %. Hence, about 6 % percent of the posts are relabelled. Most posts that are relabelled have been originally be set to the languages: “en”, unlabelled, and “en-us”. We assume that this are standard setting of the posting tools that have not been changed.
The selected German and Bavarian posts where mainly posted during day time, with two peek times at noon and late afternoon (considering time zones). The time is recorded in UTC. While Sunday shows a higher frequency of tooting, the other weekdays share similar frequencies. The days with the highest frequencies are the 247th day of the year (Sep. 4th) and the election day (Oct 8th). In general we observe more posts during the Aiwanger affair, than around the election day. The frequencies kept decreasing after the election (see fig. 5).

Left: Shows the frequency of posts from starting day to the end of records for each day (of the year). Center: Shows the frequency of posts for each weekday. Right: Shows the frequency of posts for hour of the day in UTC.
Sentiments
In the sub-sample only the parties FW, CSU, and AFD were mentioned often to contain multiple posts for most days. This situation was enhanced by adding the search for data retrieval and the longer entry list of 40 posts. As a result we got more posts for the other parties and have several posts per day for the SPD.
Fitting is done with a loess fit with a bandwidth of 0.5.
About 37 % of all toots mention the CSU as main political topic. The average sentiment (loess fit) of the CSU ranges from -0.5 to -0.4. About 44 % percent of the posts’ main topic is the FW. The average sentiment (loess fit) for the FW is around -0.5. The AFD was in twelve percent of all filtered posts. The loess fit of the sentiment is in the range of -0.4 (see fig. 6).

Sentiments for the party
CSU visualized
at the publishing day.

Sentiments for the party
FW visualized
at the publishing day.

Sentiments for the party
AFD visualized
at the publishing day.
The count of mentioned parties over the full filtered sample is listed in tab. 5. Beside the percentage based method, we also show the percentage of all posts weighted by the count of followers of each author. Finally, we also show the percentage posts by Bavarian users.
| Party | Percentage | Percentage Followers | Percentage Bavaria | Election Result |
|---|---|---|---|---|
| AFD | 11.7 % | 18.4 % | 11.0 % | 14.6 % |
| CSU | 30.7 % | 28.5 % | 32.6 % | 37.0 % |
| FDP | 1.9 % | 0.7 % | 1.3 % | 3.0 % |
| FW | 47.7 % | 45.3 % | 49.1 % | 15.8 % |
| Gruene | 3.0 % | 1.2 % | 1.8 % | 14.4 % |
| Linke | 1.3 % | 1.7 % | 1.8 % | 1.5 % |
| SPD | 3.7 % | 4.1 % | 2.1 % | 8.4 % |
These percentages are 30 percent points too high for Freie Waehler.
Therefore, we estimate the same data again, but only within the time period from
day of the year 260 (Sep. 17th) to 280 (Oct. 7th), after the Aiwanger affair calmed down to the day before the election (see tab. 6).
| Party | Percentage | Percentage Followers | Percentage Bavaria | Election Result |
|---|---|---|---|---|
| AFD | 20.6 % | 46.9 % | 17.3 % | 14.6 % |
| CSU | 45.3 % | 30.5 % | 42.7 % | 37.0 % |
| FDP | 1.3 % | 0.3 % | 0.9 % | 3.0 % |
| FW | 21.6 % | 14.9 % | 28.2 % | 15.8 % |
| Gruene | 5.9 % | 4.1 % | 6.4 % | 14.4 % |
| Linke | 0.7 % | 0.0 % | 0.9 % | 1.5 % |
| SPD | 4.6 % | 3.2 % | 3.6 % | 8.4 % |
This increases the accuracy for the FW and SPD, but still strongly underestimates the Gruene party.
Finally, we add the condition to only keep the most positive posts per user. This is closer to a voting intent. We still overestimate the CSU and FW. All this filtering results in very small supports for Bavarian authors (see tab. 7).
| Party | Percentage | Percentage Followers | Percentage Bavaria | Election Result |
|---|---|---|---|---|
| AFD | 18.7 % | 43.2 % | 16.1 % | 14.6 % |
| CSU | 45.9 % | 31.1 % | 38.1 % | 37.0 % |
| FDP | 1.0 % | 0.7 % | - | 3.0 % |
| FW | 22.0 % | 14.1 % | 30.6 % | 15.8 % |
| Gruene | 6.4 % | 2.0 % | 8.1 % | 14.4 % |
| Linke | 1.4 % | 0.3 % | 1.6 % | 1.5 % |
| SPD | 4.6 % | 8.8 % | 4.8 % | 8.4 % |
After the additional filtering, the FDP was not mentioned by Bavarian users.
In addition, we estimate the frequencies, weighted by the follower count of its authors. This results in a strong overestimation of the AFD. The average error per party is well above the other methods tested here.
Removing data before the Aiwanger affair reduced the average error per party from the range of 8 to 9 percentage points, to 5 percentage points. Using the most positive sentiment per author again reduced the error to 4.4 (Bavaria) and to 4.7 (other German regions) percentage points. In the election result, the mentioned parties only add to 94.7 % of all valid votes, due to smaller parties we did not monitor. If we correct our prediction by the 94.7 %,
we do not get an decreased overall error for the posts in tab. 5. But in the datasets that exclude the period of the Aiwanger affair (tab. 6 and 7), we decrease the average error by 10 to 12 %. Hence our best prediction was increased from an average error of 4.4 percentage points, to 4.o percentage points.
Compare Sentiments and Polls
The sentiment is shifted from the range -1 to 1 to the range 0 to 1 (see formula (1)). The sentiments of the posts were aggregated for the same day or calendar week, with the mean function. Missing values are filled forward first and than backward.
$$ Sn(party) = (S(party) + 1) / 2 ...(1) $$Then the sentiment is weighted by the sum of the sentiment of all parties for the same week (see formula (2)). This is used as a measure to correct the sentiment by how well the sentiment of other parties is in the same time period. If comparing the daily aggregate and the weekly aggregate, we can see that the variance is much higher for the sentiment compared to the polls. This is strongly reduced by the weekly aggregates (see fig 8.)
$$ Sp(party) = Sn(party) / Σparty Sn ...(2) $$
Comparision of the daily timelines polls and sentiment for the party FW.

Comparision of the weekly timelines polls and sentiment for the party FW.
We would underestimate the result of the CSU at any given point in time. The result for the AFD is relative close, while we overestimate smaller parties (see fig. 9).

Comparision of the weekly timelines polls and sentiment for the party AFD.

Comparision of the weekly timelines polls and sentiment for the party CSU.
The graph that compares the polling result to the sentiments (fig. 10), shows that the main dependency is the party itself.

Showing the relation of the polls
for each party versus their sentiment.
The offset of the cross correlation for the timelines for all parties is zero.
The support of Bavarian samples, is already small. We therefore only group by calendar week, or the region. Group by both would reduce the support again thus increase the error for small parties.
For the calendar week 40 (week of the election) the sentiment based election prediction is shown below. This approach strongly overestimates smaller parties. The predictions of all parties are much closer to each other. In addition, to the bare sentiment for calendar week 40, we apply a linear fit between the polls and the weekly sentiment $ S_p $ for the last six election weeks.
The parties are one-hot encoded. Which means each Party is an attribute. This Attributes encodes, whether this post is about the party as 1 (true) or 0 (false). The poll result depend much stronger on the party itself than on the weekly averaged sentiment. The slope for the sentiment is only 0.024. Which means that in the model the sentiment only accounts for a maximum of 2.4 percentage points. Everything else is depending on the party itself. R²-score on the test dataset is 0.997.
In addition, we show the result of the fit for a ridge regression with alpha=0.1. The fits for calendar week 40 is shown in the table below.
The grid search for different alpha showed the best result for alpha = 0, which is a normal linear fit.
The ridge regression regularizes higher weights and thus increases smaller weights to reduce the error. This reduces the weights for the larger parties and increases the weights for smaller parties. In addition the influence of the sentiment was increased to 9.9 percentage points. This meanly increases the error if the linear fit already underestimates the election results, and decreases it if the result was overestimated by the linear fit (see tab. 8).
The average error for the linear fitted result is 0.40 percentage points and 0.59 % for the ridge regression. This is less than the error of the last polls
of Forschungsgruppe Wahlen and INSA. The error of the linear fit is about the same size as average error over all polls of the last six weeks, which is 0.39.
| Party | Sentiment KW 40 | Average Polls | Linear Fit KW 40 | Ridge Fit KW 40 | Election Result |
|---|---|---|---|---|---|
| AFD | 15.8 | 13.9 % | 14.1 % | 13.7 % | 14.6 % |
| CSU | 15.4 | 36.4 % | 36.4 % | 35.7 % | 37.0 % |
| FDP | 12.7 | 3.4 % | 3.4 % | 3.2 % | 3.0 % |
| FW | 13.7 | 16.0 % | 16.2 % | 15.1 % | 15.8 % |
| Gruene | 19.2 | 14.6 % | 14.6 % | 14.5 % | 14.4 % |
| Linke | 8.4 | 1.4 % | 1.4 % | 1.0 % | 1.5 % |
| SPD | 14.7 | 9.0 % | 9.0 % | 8.9% | 8.4 % |
Discussion
Each poll has at least a sample size of 1000 people. In contrast,we monitored 4921 posts that are from other regions of Germany, from 1728 users. But from Bavaria we only got 549 posts, written by 160 users, which results very likely in an unrepresentative sampling.
Most toots about the FW are made at the start of the sampling period when the Aiwanger affair was the main topic of the election.5
The number of posts we evaluated is very low. The ability to distinguish the Bavarian posts from other German posts is very limited. The differences that are shown in the frequencies thus have limited information value.
The changes in polls results have to be larger than the resolution and error of the polls themselves. The resolution given by the source is 1 %. The errors of polls are not given by each party, they are often given as two percentage points for parties that reach 10 % and an error of three percentage points, at 50 %.21 Because, the changes in the pools are slow, a longer time frame is needed to accumulate changes that are above this resolution or error.
Daily sentiment analysis shows more noise than poll results. Weekly or monthly averages have to be used, due to the higher number of samples on longer time frames, but also due to the fact that sentiments are not voting intentions. While daily changes in politics might show strong reactions in sentiment, we assume that voting intentions might only shift on a longer time period.
We have a lower count of samples for the parties SPD, Buendis 90/ Gruene, and FDP that govern at the federal level. Thus, sentiment analysis on a national scale is more promising.
We tried to predict election result with two different versions:
- Frequency based,
- Sentiment based.
The frequency based version favoured the FW strongly above their election result by about 30 percentage points. After removing all mentions in the period of the Aiwanger affair the error could be greatly reduced. We still strongly favour the FW, 14 to 20 percentage points above their potential. Probably due to the strongly local factor of the party. We assume that it is less overshadowed by national politics as other parties.
If we compare the error of the predicted election result to the actual election result, we get an average error of four to nine percentage points per party. The best prediction is made by most positive post of Bavarian authors recorded between Sep. 17th and Oct. 7th. for the highest sentiment per user with an average error of 4.4 percentage points. This is done to emulate the voting intent. We assume that the voting intent can be better emulated if we filter out negative sentiment.
Removing the time period of the Aiwanger affair reduces the average error from 9 to 5 percentage points. Comparing the posts of Bavarians to other German authors, we only slightly decrease the error.
Considering the sentiment based method we can see that the weekly sentiment for the parties CSU, FW and AFD is very similar. This is also true for the other parties like SPD. The sentiment for the Buendis 90 / Gruene is slightly higher.
Filtering by the most positively mentioned party per author, reduces the error slightly. We assume that while not all parties are mentioned by each user, the true vote intent is still partially hidden. Therefore, we might select the least negatively mentioned party instead.
The roberta base language detection model lists a F1-score of 0.967 for German and 1.000 for English.15 The German language Sentiment model lists an overall F1-micro score of 0.9639.16 The English language Sentiment model lists an F1-score of 0.72.18 Still, the models can not detect sarcasm, as this needs a lot of background knowledge. This is considered a different task in the field of text mining.18
About 10 % of all kept posts were labelled as Bavarian. We do not know whether this is due to lower number of Bavarian people who use Mastodon or whether they use generalised instances, so that we could not distinguish them as Bavarian users. We tried to mitigate this problem with the self-disclosure in user fields and user texts. We did not try to classify the users by their language usage.
The best result was based on the polling data. The average of the polls of the last six weeks before the election resulted into very small error of 0.39 percentage points per party. Similar results could be achieved by a fit of the polls of each party versus the sentiment analysis. The dependency of the poll result from the sentiment was small. It has to be tested whether this effect can be repeated for other elections.
Conclusion
The frequency analysis has been enhanced by filtering early and late posts and only keeping the most positive post per user. This reduced the error to 4.4 percentage points. To better emulate voting intent, we would need to further filter out negative posts. We propose to reduce the error by finding the best cut-of at which sentiments are considered too negative.
We see strong problem for using Mastodon as a basis for polling (regional) elections. We assume that for national elections Mastodon might be a better data source. The number of toots in the Bavarian state election 2023 was relatively low. We only got a high number of posts during the Aiwanger affair, which in turn added a bias to the frequencies for all parties.
In addition, we assume that the user base is not representative for the socio-demographics of Germany or any German state. Wherefore, we propose a two layered strategy to mitigate this by applying a weighted average of the user data. We propose that gender can be extracted from user data like user name, user fields and user texts. For users that do not share this information we propose an image classification. Similar we propose an image classification to retrieve the age of the users. For images with no person or multiple persons, we assume a random gender and a random age (drawn from the image/user distribution). Some models for the age a gender classification are listed at paperswithcode and also in the ONNX model zoo. This would enable us to compare the user demographics of sample to the Bavarian Census.22
Appendix
Bavaria Demographics
Bavaria has about 13.3 M and slightly more women (50.5 %).22 This is due to the age distribution of its citizen, caused by a higher mortality rate of men at higher ages. The peer group aged 40 to 50 is the first one with more than 50 % women. All younger peer groups show an surplus of men by two to five percent. On the other hand, the peer group of age 75 or older shows a surplus of women of about 17 %.
Demographics Sample
In the sub-sample we encountered following keys in the user fields that correspondent with the age of the user, listed in tab. 9.
| Category | Keywords |
|---|---|
| Age | age, Alter |
| Birth | born, Geburtstag |
We encounter keys that describe the gender/sex are listed tab 10. by their group.
| Category | Keywords |
|---|---|
| Gender | Gender, Geschlecht, Sexualität |
| Pronouns | Pronom, Pronomen, Pronoun, Pronouns, Pronomina, Pronoms |
| Other | Wer |
The values for the user fields concerning gender/sexuality are grouped by sex in tab. 11.
| Category | Values |
|---|---|
| Male | he, him, his, er, ihm, ihn, sein |
| Female | she, her, sie, ihr |
List of Bavarian Instances
The lists of Bavarian instances has been adapted from the openstreetmap Mastodon Near me.8 The instances are grouped and listed in tab. 12.
| Category | Values |
|---|---|
| Cities | muenchen.social, augsburg.social, nuernberg.social, wue.social, ploen.social, mastodon.dachgau.social |
| Other | mastodon.bayern, sueden.social |
wue.social is the instance for the city of Wuerzburg. sueden.social is a more general instance for southern Germany, but we assume that the overlapping and regional proximity lead to a similar sentiment.
List of Keywords in Table Fields that Transcode Locations
Some users user there user fields, to contain some information about there location. The user fields keys that are used to filter are listed by there category in tab. 13.
| Category | Values |
|---|---|
| Home | “heimat”, “heimathafen”, “heimatort”, “home”, “wohnhaft”, “wohnort”, “wohnt in”, “zuhause” |
| Birthplace | “born where”, “herkunft” |
| Region | “bundesland”, “country” |
| Other | “adresse”, “city”, “location”, “ort”, “standort”, “wahlkreis”, “wo”, “📍” |
Monitoring Interruptions
The monitoring service was interrupted on Sep. 30th 2023 for about 20 hours and on Oct. 7th 2023 for the update. A longer interruption took place from Oct. 28th to 31th and lasted about 85 hours.
Tech stack
Saving Mastodon data into a SQLite database is done with an Elixir project with mix. The Mastodon api is called with HTTPoison. Ecto applied to write the reply into a SQLite3 database. Cron is utilised to hourly trigger the api calls with Quantum.
The data evaluation is done with the Nx framework. The first version of Nx was released 01/06/2022. Nx enables the numerical computation in Elixir and is used for Machine Learning (Scholar) and Deep Learning libraries (Axon), for instance with the EXLA compiler as backed. The packages are still in development and sometimes new functions and fixes were just released during the project. For instance the week_of_year function was created for this.
References
Rochko, Eugen: Annual Report 2022, https://blog.joinmastodon.org/2023/10/annual-report-2022/, Version: Dec. 10 2023. ↩︎
ActivityPub, https://en.wikipedia.org/wiki/ActivityPub, Version: Dec. 10 2023. ↩︎
FediDB - Fediverse Network Statistics, https://fedidb.org/, Version: Dec. 10 2023. ↩︎
Mastodon Users (@mastodonusercount@mastodon.social),https://mastodon.social/@mastodonusercount, Version: Dec. 10 2023. ↩︎
Hubert Aiwanger, https://en.wikipedia.org/wiki/Hubert_Aiwanger, Wikipedia, : Dec. 10 2023. ↩︎ ↩︎
Auer; Katja, Beck; Sebastian: Glas; Andreas, Ott; Klaus: Hubert Aiwanger soll als Schüler ein antisemitisches Flugblatt verfasst haben, Süddeutsche.de, Version: Dec. 15 2023. ↩︎
Koch, Wolfgang: Ergebnisse der ARD/ZDF-Onlinestudie 2023, https://www.ard-zdf-onlinestudie.de/files/2023/MP_26_2023_Onlinestudie_2023_Social_Media.pdf, Version: Dec. 10 2023. ↩︎
Mastodon Near Me - Global Mastodon server list by country and region - uMap, https://umap.openstreetmap.fr/en/map/mastodon-near-me-global-mastodon-server-list-by-co_828094, Version: Dec. 10 2023. ↩︎ ↩︎ ↩︎
Find where to sign up for the decentralized social network Mastodon., https://joinmastodon.org/servers, Version: Dec. 10 2023. ↩︎
Sentiment analysis, https://en.m.wikipedia.org/wiki/Sentiment_analysis, Wikipedia, : Dec. 15 2023. ↩︎
Pekar, Viktor; Najafi, Hossein, Binner, Jane M., Swanson, Ridley; Rickard, Charles, Fry, John: Voting intentions on social media and political opinion polls, Government Information Quarterly 39 (2022), 1-50. ↩︎
Bohrn, Brandon: The Evolution of Germany’s Political Spectrum | Politics & Society, https://bfna.org/politics-society/the-evolution-of-germanys-political-spectrum-19esvea4sk/, Version: Dec. 13 2023. ↩︎ ↩︎
Landtagswahl in Bayern 2023: Kandidaten, Themen, Termin, https://www.br.de/nachrichten/bayern/landtagswahl-in-bayern-2023-termin-themen-kandidaten,TMD4uSM, Version: Dec. 10 2023. Bayerische Linke kürt Adelheid Rupp als Spitzenkandidatinhttps://www.br.de/nachrichten/bayern/bayerische-linke-kuert-adelheid-rupp-als-spitzenkandidatin,TZXl5yd, Version: Dec. 10 2023. ↩︎
OpenData, https://geodaten.bayern.de/opengeodata/OpenDataDetail.html?pn=verwaltung, Version: Dec. 10 2023. ↩︎
papluca/xlm-roberta-base-language-detection · Hugging Face, https://huggingface.co/papluca/xlm-roberta-base-language-detection, Version: Dec. 10 2023. ↩︎ ↩︎
oliverguhr/german-sentiment-bert · Hugging Face, https://huggingface.co/oliverguhr/german-sentiment-bert, Version: Dec. 10 2023. ↩︎ ↩︎
Tokenizer, https://platform.openai.com/tokenizer, Version: Dec. 10 2023. ↩︎
finiteautomata/bertweet-base-sentiment-analysis · Hugging Face, https://huggingface.co/finiteautomata/bertweet-base-sentiment-analysis, Version: Dec. 10 2023. Pérez, Juan Manue;, Rajngewerc Mariela; Giudici, Juan Carlos; Furman, Damián A.; Luque, Franco; Alemany, Laura Alonso; Martínez, María Vanina: pysentimiento: A Python Toolkit for Opinion Mining and Social NLP tasks,https://arxiv.org/abs/2106.09462, Version: Dec. 10 2023. ↩︎ ↩︎ ↩︎
Zhang, Shiwei; Zhang, Xiuzhen; Chan, Jeffrey; Rosso, Paolo: Irony detection via sentiment-based transfer learning, Information Processing & Management 56 (2019), 1633-1644. ↩︎
Sonntagsfrage zur Landtagswahl 2023 in Bayern, https://www.wahlrecht.de/umfragen/landtage/bayern.htm#fn-bp}, Version: Dec. 10 2023. ↩︎
ARD-DeutschlandTrend: Zufriedenheit mit Kanzler Scholz auf Rekordtief, https://www.tagesschau.de/inland/deutschlandtrend/deutschlandtrend-3410.html, Version: Dec. 12 2023. ↩︎
Bevölkerung in den Gemeinden Bayerns nach Altersgruppen und Geschlecht, https://www.statistik.bayern.de/mam/produkte/veroffentlichungen/statistische_berichte/a1310c_202200.pdf, Bayerisches Landesamt für Statistik, Version: Dec. 10 2023. ↩︎ ↩︎
Last modified on 2023-12-15